
Contente
Juntamente com seu novo processador gráfico Mali-G77 e o processador de vídeo Mali-D77, a Arm apresentou seu mais recente design de CPU de alto desempenho - o Cortex-A77. Assim como no Cortex-A76 do ano passado, o Cortex-A77 foi projetado para aplicativos de nível premium que exigem o baixo consumo de energia da Arm. Tudo, desde smartphones a laptops e muito provavelmente além.
Com o Cortex-A77, a Arm objetivou o aumento máximo de desempenho por instruções / ciclo / relógio (IPC) que poderia gerenciar sobre o Cortex-A76. As frequências do relógio, o consumo de energia e a área são projetados para permanecer aproximadamente no mesmo estádio, mas o novo núcleo pode processar mais instruções ao mesmo tempo. Para fazer isso, a Arm projetou um núcleo ainda mais amplo do que no ano passado e fez várias melhorias para manter o núcleo da CPU alimentado com o que fazer. Mas antes de chegarmos a isso, vamos nos aprofundar na visão geral de alto nível e nos números de desempenho.
Atingindo metas de desempenho
Em agosto de 2018, Arm compartilhou de maneira incomum um roteiro de CPU até 2020. Desde o Cortex-A73 de 2016 até o design "Hercules" de 2020, a empresa promete um aumento de 2,5 vezes no desempenho da computação. Uma boa parte dessa enorme projeção foi realizada com a grande mudança de microarquitetura com o Cortex-A76, velocidades de clock modernas mais altas e a mudança de 16 para 10 e agora fabricação de 7 nm com 5 nm a seguir. Cerca de 1,8x dos ganhos do roteiro já foram alcançados no ano passado, e o Cortex-A77 fornece um aumento de aproximadamente 20% no IPC. Isso nos coloca no caminho da meta de 2,5x da Arm, embora os dispositivos móveis com orçamentos térmicos e de energia limitados não esperem ver todos esses ganhos.
Para comparação, o Cortex-A76 do ano passado proporcionou um aumento de 30 a 35% em relação ao Cortex-A75. Este ano, estamos olhando para um ganho de IPC mais silencioso, mas ainda significativo, de 20% entre o A77 e o A76. Esta é uma boa notícia, pois significa mais desempenho, mantendo restrições térmicas e de energia semelhantes às de antes. A desvantagem é que o A77 é cerca de 17% maior que o A76, então custará um pouco mais em termos de área de silício. Se você deseja uma comparação com os líderes de desktop, a AMD conseguiu um aumento de 15% no IPC entre o Zen2 e o Zen +, enquanto o IPC da Intel permaneceu praticamente estático por anos.É claro que estamos falando de diferentes segmentos de mercado aqui, mas isso demonstra como a equipe de design de CPU da Arm obteve ganhos impressionantes nas últimas gerações.
Um aumento de 20% no desempenho está em oferta para os SoCs de última geração baseados em Cortex-A77
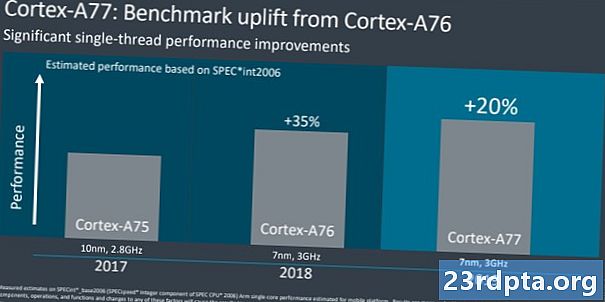
O ponto principal aqui é que o A76 marcou uma grande mudança na microarquitetura com enormes ganhos de desempenho, enquanto voltamos às melhorias no nível de otimização com o A77. Com isso fora do caminho, vamos mergulhar no que há de novo no Arm Cortex-A77.
Cortex-A77 se baseia na microarquitetura A76
A chave para entender a diferença entre o Cortex-A77 e o A76 é entender o que se entende por um design principal "mais amplo". Basicamente, estamos falando da capacidade de executar mais instruções para cada ciclo de clock, o que aumenta a taxa de transferência do núcleo. Há duas partes importantes para corrigir isso: aumentar o número de unidades de execução para fazer o processamento e garantir que essas unidades sejam mantidas bem alimentadas com dados. Vamos começar com a última parte e focar nas partes de envio, cache e preditor de ramificação do SoC.
O Cortex-A77 vê um aumento de 50% na largura de expedição, até seis instruções por ciclo, de quatro com o A76. Isso significa mais instruções para o núcleo de execução de cada ciclo de clock para maior potencial de desempenho. A janela de execução fora de ordem também é maior como resultado, aumentando para 160 entradas para expor mais paralelismo. Há um cache de instruções familiar de 64K, enquanto o BTB (Branch Target Buffer), que contém endereços para o preditor de ramificação, é 33% maior do que antes para lidar com o crescimento em instruções paralelas. Nada de anormal aqui, é essencialmente uma versão mais ampla do design do ano passado.
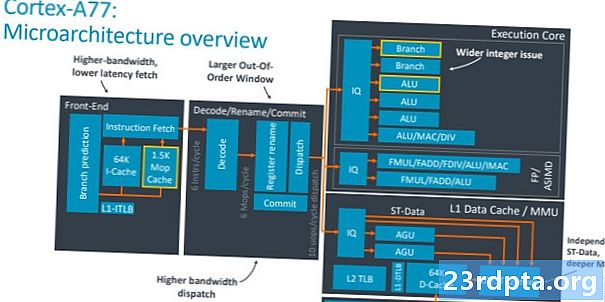
A adição de front-end mais intrigante é o novo cache MOP de 1,5K, que armazena MOPs (macro-Ops) que são realimentados a partir da unidade de decodificação. A arquitetura de CPU da Arm decodifica as instruções do aplicativo de um usuário em macro-operações menores e depois nas micro-operações que o núcleo de execução entende. Você pode ver isso no diagrama acima na seção de decodificação. O cache do MOP é usado para reduzir a penalidade de custo de desvios e descargas perdidas, à medida que você mantém as macro-ops em vez de decodificá-las novamente e aumenta a taxa de transferência geral do núcleo. Buscas no MOP em vez de no cache i ignoram o estágio de decodificação, economizando um ciclo. Arm afirma que o cache do MOP pode atingir uma taxa de 85% ou mais de acertos em uma variedade de cargas de trabalho, tornando-o um complemento muito útil ao cache i padrão.
Movendo-se para a parte principal da execução da CPU, observe a adição de uma quarta ALU e uma segunda unidade de Filial. Essa quarta ALU aumenta em 50% a largura de banda geral de processamento de números do processador. Essa ALU adicional é capaz de instruções básicas de um ciclo (como ADD e SUB), além de operações inteiras de dois ciclos, como uma multiplicação. Duas das outras ALUs podem lidar apenas com instruções básicas de um ciclo, enquanto a unidade final é carregada com operações matemáticas mais avançadas, como divisão, acumulação múltipla etc. A segunda unidade de ramificação dentro do núcleo de execução duplica o número de ramificações simultâneas. o core pode lidar, o que é útil nos casos em que duas das seis instruções enviadas são saltos de ramificação. Isso soa um pouco estranho, mas os testes internos da Arm revelaram benefícios de desempenho com a adoção desta segunda unidade.
O Cortex-A77 oferece paralelismo aprimorado e uma nova visão sobre caches de pré-busca
Outros ajustes no núcleo da CPU incluem a adição de um segundo pipeline de criptografia AES. Os pipelines de armazenamento de dados agora apresentam portas de emissão dedicadas para dobrar a largura de banda de emissão de memória. Essas portas foram compartilhadas anteriormente com as ALUs, que às vezes podem se tornar um gargalo. Há também um aperfeiçoador de dados de última geração para melhorar a eficiência de energia e, ao mesmo tempo, aumentar a largura de banda da DRAM do sistema.
Parte desse sistema no Cortex-A77 também possui um novo sistema de pré-busca "sensível ao sistema". Isso melhora o desempenho da memória com base na ampla variedade de contagens de núcleos da CPU, capacidades e latências de cache e configurações do subsistema de memória nos dispositivos finais. O hardware dedicado às conversas com a Dynamic Scheduling Unit (DSU) como parte de um cluster de CPU DynamIQ, que monitora o uso do cache L3 compartilhado. O núcleo possui níveis dinâmicos de distância e agressividade para reduzir a utilização do cache em situações em que a largura de banda L3 é limitada por outros núcleos da CPU. Núcleos de desempenho mais alto, como o Cortex-A77, são mais propensos a saturar o acesso do DSU à memória, enquanto é improvável que núcleos de menor potência, como o A55.

Reunindo tudo isso
Há muitas pequenas mudanças no Cortex-A77 que resultam em algumas diferenças substanciais em relação ao seu antecessor. Em poucas palavras, o novo cache MOP do A77, combinado com uma janela de instruções mais ampla e mais longa, ajuda a manter as unidades ALU, Filial e de memória reforçadas ocupadas com o que fazer. O design poderoso da Cortex-A76 foi ampliado para melhorar ainda mais sua taxa de transferência com o A77, sem depender de velocidades de clock mais altas.
O maior aumento de desempenho do Cortex-A77 chega na forma de um número inteiro e matemática de ponto flutuante. Isso é confirmado pelos benchmarks internos da Arm, que mostram um aumento de desempenho de 20 a 35 por cento nos benchmarks SPEC inteiro e de ponto flutuante, respectivamente. As melhorias na largura de banda da memória situam-se entre 15 e 20%, novamente destacando que os maiores ganhos ocorrem na forma de processamento de números. No geral, essas melhorias dão ao A77 uma elevação média de 20% em relação à geração anterior. Também podemos ver ganhos adicionais, mais marginais, como resultado de processos de fabricação de 7nm mais avançados no final deste ano ou no início de 2020.
Em termos de smartphones, os SoCs equipados com Cortex-A77 destinam-se a produtos de alto desempenho e emblemáticos. A Arm espera esperar que o projeto da casa de força utilize 4 + 4 bits. Dado o aumento da taxa de transferência e o ligeiro aumento do tamanho da área do A77, provavelmente veremos os designers de SoC continuarem na tendência 1 + 3 + 4 ou 2 + 2 + 4. Com um ou dois núcleos grandes e poderosos, com caches maiores e relógios mais altos, com backup de 2 ou 3 núcleos A77 com tamanhos de cache menores e relógios mais baixos para economizar energia e área. Por fim, o Cortex-A77 significa coisas boas para chips de smartphones e o crescente mercado de laptops Arm sempre conectados. Fique de olho nos anúncios de silicone ainda este ano.


